MySQL - 큰 테이블을 다루는 jdbc 활용법 ①
데이터베이스에서 한 번에 많은 데이터 읽어야 한다면 어떻게 해야할까?
왜 이런 작업이 필요로 하는가?
간단한 통계 자료를 생각해보자.
우선, 통계 자료를 만들기 위해서는 축적된 데이터가 필요하다. 축적된 데이터는 10만 row가 될 수 도 있고, 1000만 row가 될 수 있고, 1억 row가 될 수 있다. 그리고 데이터를 기반으로 여러가지 결과를 도출해낼 것 이다. 그런데 사용자가 요청할 때마다 매번 결과를 도출해낼 것인가? 아니다. 하루에 한번이던, 한 주에 한번이던 지정한 시간에 맞춰 주기적으로 작업을 수행할 것 이다. 물론 요즘에는 이를 해결하기 위한 다양한 메커니즘과 오픈소스를 제공하기 때문에 굳이 MySQL 같은 RDB를 활용하지 않고도 가능하다. 하지만, 오히려 배보다 배꼽이 더 커질 수 있기 때문에 RDB로 이와 같은 작업을 해결해 보고자 한다. 보통 이를 batch-processing이라 한다.
벤치마킹 : Spring Batch
그나마 아는 Spring Framework를 참고해보자.
Spring Framework은 많은 노하우와 모범 사례가 녹아있는 자바 프레임워크 중 하나로, 그 중, Spring Batch를 훑어보면 RDB를 활용하는 몇 가지 방법이 있다. 크게는 총 2가지를 지원하는데 **Cursor를 활용하는 방법**과 **Paging 처리하는 방법**이다.
글의 주제가 Spring이 아니기 때문에 'Cursor나 Paging을 활용하면 된다'정도 힌트만 가지고 다음 단계로 넘어가자. 또한 이 글에서는 Cursor만 활용해볼 것 이다.
Cursor 활용하기
데이터베이스 커서(Cursor)는 일련의 데이터에 순차적으로 액세스할 때 검색 및 "현재 위치"를 포함하는 데이터 요소이다. (참고: 데이터베이스 커서 - 위키백과)
여기서 고려해야할 점은 적절한 갯수만큼 row(데이터 요소)를 가져오는 것이다. 한번에 그 많은 row를 가져온다고 생각해보자. 아마도 메모리 사용량이 초과하여 OOM(Out Of Memory)가 발생할 것이다. 반대로 적은 갯수 가져온다고 생각해보자. 아마도 굉장히 오래 걸릴 것이다. 이를 설정할 수 있는 방법은 fetchSize를 지정하는 것이다.
fetchSize 지정하기
순수 JDBC를 사용하면 다음과 같이 지정할 수 있다.
Statement stmt = connection.createStatement("select ... from ...");
stmt.setFetchSize(fetchSize);
// ...
그럼 이제 설정이 끝난걸까? 간단하게 테스트를 해보자. 여러 값을 적용하여 소요시간을 측정해보면 될 것 이다.
소요시간 측정
10만 row가 들어있는 간단한 테이블을 준비 해놓고 Integer.MIN_VALUE, 5, 10, 50, 100, 500, 1000, 2500, 5000 ��순으로 측정해 보았다. 결과는 이상하게도 fetchSize와 무관하게 서로 비슷한 소요시간이 측정되었다. (약 320 ~ 400ms)
useCursorFetch
여러 삽질을 하고 결국 문서를 통해 해답을 얻을 수 있었는데, 이는 바로 useCursorFetch=true를 지정하는 것이다. (참고)
Connection connection =
DriverManager.getConnection("jdbc:mysql://localhost/?useCursorFetch=true", "...", "...");
Statement stmt = connection.createStatement("select ... from ...");
stmt.setFetchSize(fetchSize);
// ...
mysql-connector-java@8.0 - ResultsetRowsCursor.fetchMoreRows()를 보면 fetch가 어떻게 동작하는지 이해할 수 있다.
다시 시간 측정
| fetch size | time(ms) |
|---|---|
| Integer.MIN_VALUE | 682 |
| 5 | 12367 |
| 10 | 6401 |
| 50 | 1632 |
| 100 | 1115 |
| 500 | 606 |
| 1000 | 527 |
| 2500 | 508 |
| 5000 | 464 |
물론 하드웨어 사양, 환경마다 다르겠지만 fetchSize에 따라 서로 다른 소요시간이 나온 것을 볼 수 있다. 앞서 예상했던 것 같이 너무 작으면 굉장히 오랜 시간이 소요되므로 적절한 값을 지정해야 한다.
보다 디테일하게 분석하기
앞에서 같이 삽질을 하지 않기 위해 소요시간 �이외에 보다 디테일한 분석을 해보자. 메모리 사용량은? 패킷은?
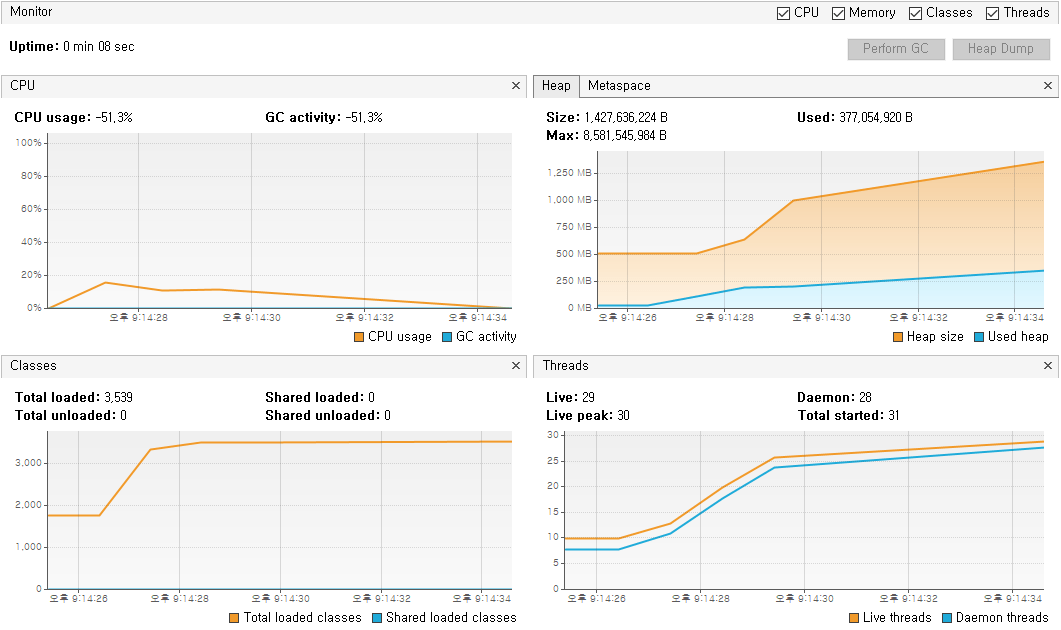
메모리 사용량 (feat. VisualVM)
Java Profiling Tool 중 하나인 VisualVM으로 대략적인 메모리 사용량을 측정해본 결과이다.
useCursorFetch=false 경우
useCursorFetch=true 경우
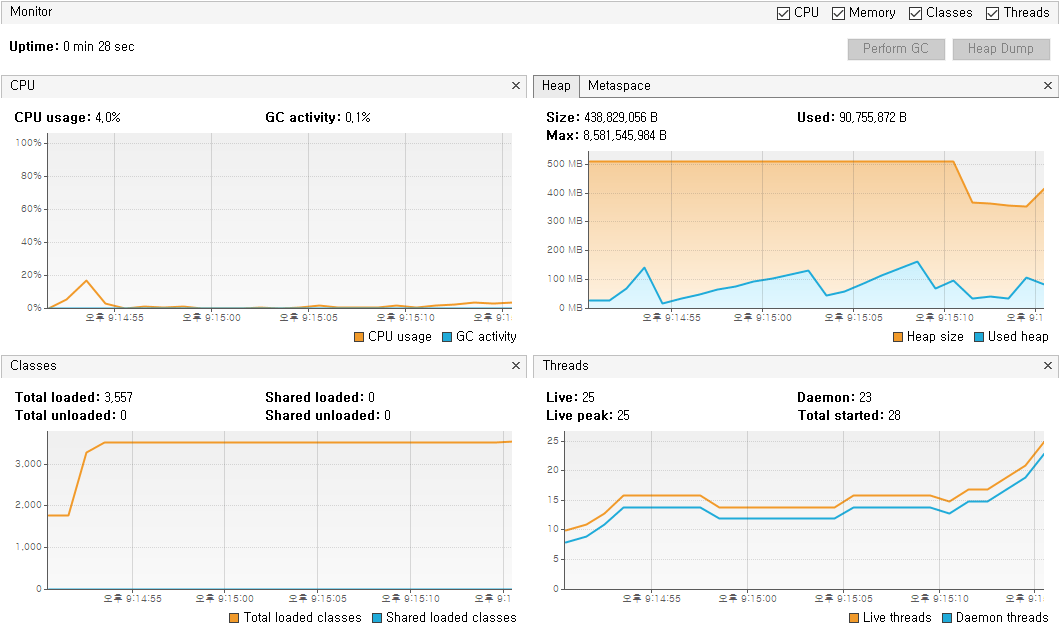
useCursorFetch=true경우, 메모리 사용량이 더 적을 것을 볼 수 있다.
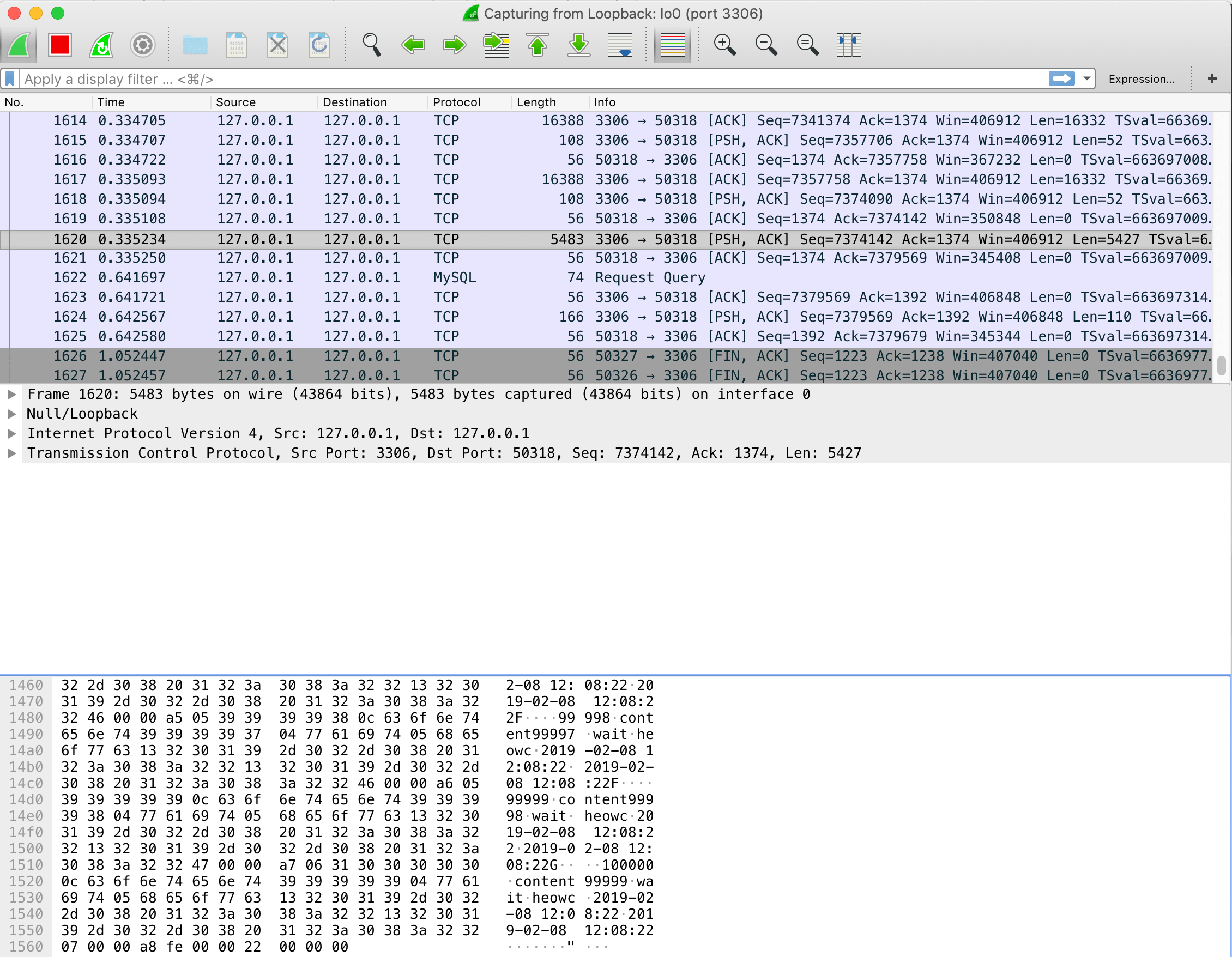
패킷 분석 (feat. WireShark)
jdbc 프로토콜 패킷을 분석하기 위해 WireShark를 활용해본 결과이다.
useCursorFetch=false 경우
useCursorFetch=true와 fetchSize=5 경우
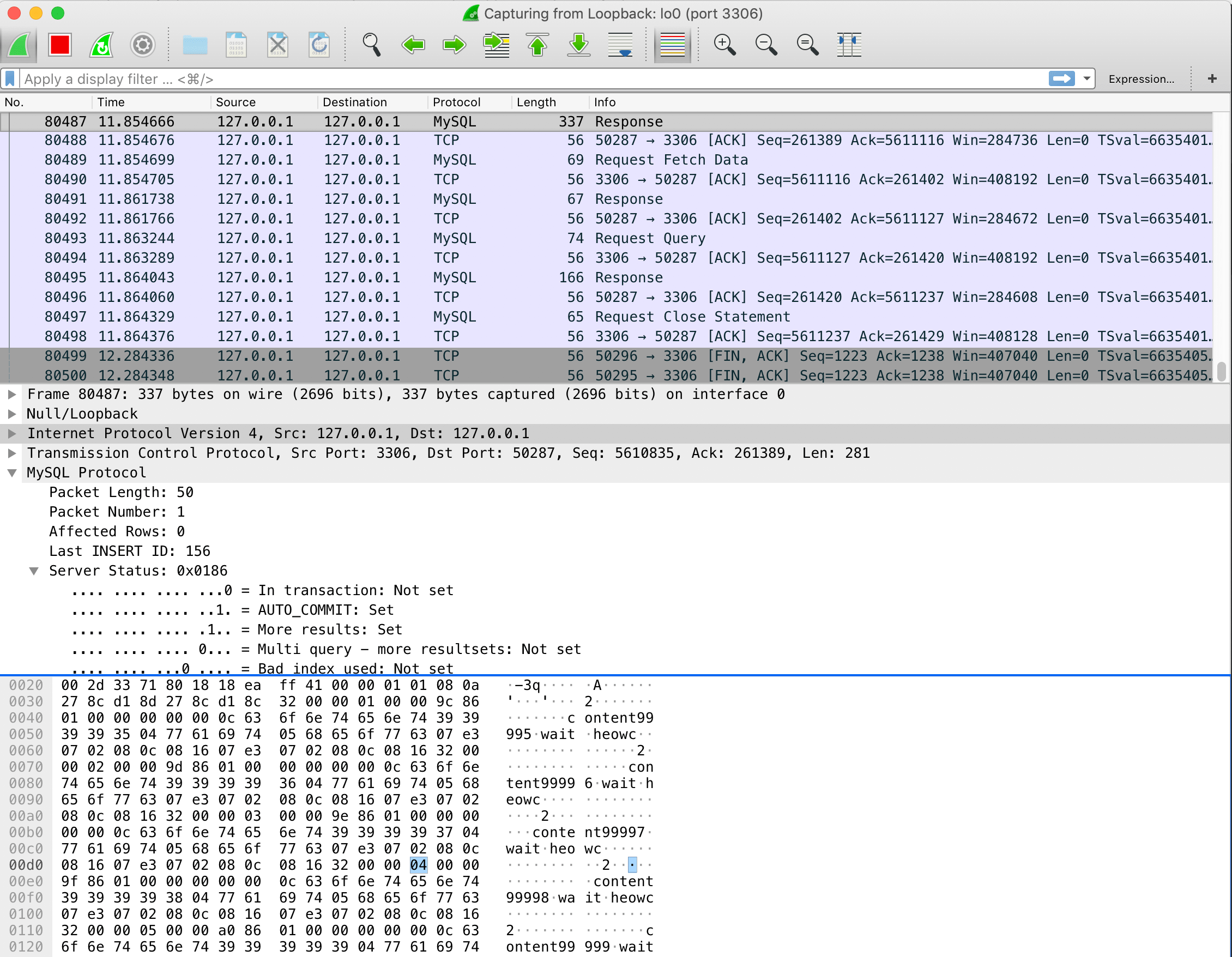
useCursorFetch=true와fetchSize=5경우,fetchSize만큼 데이터를 전달하기 때문에 네트워크 통신이 보다 많은 것을 볼 수 있다.
추가로 알게된 점
- 초반에 MariaDB를 사용했었는데 해당 JDBC 드라이버에는
useCursorFetch옵션이 없다. (다른 데이터베이스에도 없다.) 물론 fetchSize 적용 여부에 따라 메모리 사용량은 약간 다른 것을 볼 수 있는데, 이는 MariaDB JDBC 드라이버 자체에서 최적화 해주는 것이 아닐까 싶다. - 패킷 분석을 하는데 기본적으로 Secure Layer가 존재하여 제대로 분석하기 어려웠고,
sslMode=DISABLED추가하여 해당 Layer를 제거할 수 있었다. useCursorFetch=false경우의 WireShark 스크린샷을 보면 length가 16388인 패킷을 볼 수 있는데, 이는net_buffer_length의 default(= 16384)와 유사한 것을 알 수 있다. 고로, 많은 데이터를 read하더라도 네트워크 통신 자체는net_buffer_length만큼 나눠서 하는 것을 알 수 있다.- 이외에도 JDBC 드라이버 옵션으로 성능 튜닝할 부분이 상당히 많다.